The Rise of Web3 Data and What It Means for AI Development


I started doing data science on blockchain data in 2020. It began as a weekend hobby but quickly became an obsession, so much so that I quit my AI job at AWS and started doing it full-time as the first ML hire at Chainlink Labs. During the 2021-2022 period, I learned much about blockchain data structure, depth, and potential, especially in financial markets.
Fast-forward to the beginning of 2023, right after a few decentralized social protocols like Lens and Farcaster started getting initial adoption. I realized a new data type was being put on the blockchain beyond financial transactions. It felt like the beginning of something bigger for blockchains—a universal, immutable database. The diversity of data being stored went up, and most importantly, it started looking like internet data (with information on consumer web and mobile interactions on different media types).
As a data practitioner in the traditional web (“web2”), the potential of aggregating so much Web3 data became obvious. It is well known that “data has gravity,” and it is unstoppable in its growth once you “break down data silos.” Once an organization implements a data lake strategy, the next thing you know is that all the teams in that organization start creating 2x, 50x, and 100x more data than before (Proximity to existing data makes it easier to generate ideas about new insights). Even with this intuition, I am surprised about what has happened under the application and smart contract layers.
I have been building custom AI models for Web3 using this new data for the past year with a few data scientist friends. We now feel compelled to share more about these exciting trends.
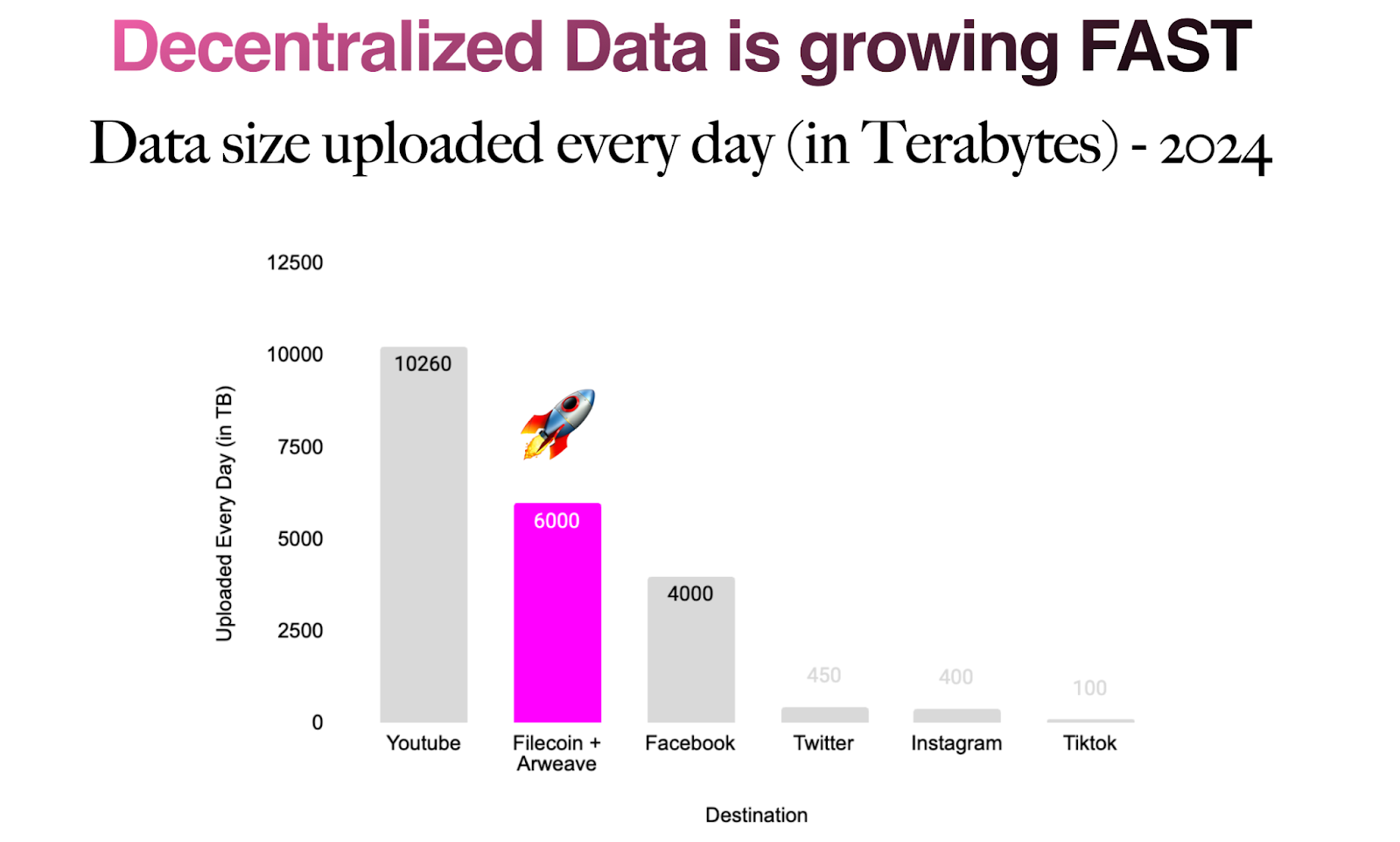
It is estimated that 64.6 EiB are uploaded to the Internet daily. Decentralized storage gets 3% of that traffic and is a top destination for exponentially growing data.
Decentralized storage datasets
As of February 2024, 1.8674 EB data was stored on Filecoin and another 155 TB on Arweave, the two leading decentralized storage solutions. More data is uploaded daily on Filecoin (5.8 PIB daily in June 2023) and Arweave (250 TB daily on average) than what’s uploaded to Facebook in a day! That is also more than what is uploaded daily to Twitter, Instagram, and TikTok combined! *
* estimating daily data uploaded to these based on these assumptions:
- 10 million tiktok 15-30 sec videos are uploaded each day, roughly 8-10 MB.
- 95 million photos and videos are shared on Instagram, roughly 80% images at 2-3 MB and 20% videos at 8-10 MB.
- 500 million tweets are sent every day on Twitter/X; roughly 20% contain images (2-3 MB), 5% contain a video (8-10 MB), and 75% only text (280 bytes)
Filecoin vs. Arweave data composition
It is important to understand in detail what data type has been uploaded to these decentralized storage platforms, as that tells a story about the different Web3 use cases developers or “archivers” had in mind.
Filecoin, which leverages the composability of the IPFS system, has seen wider adoption with institutions. Programs like Filecoin Plus attracted large internet datasets. Only a proportion of those are Web3 / crypto related, and are focused on blockchain archiving and NFT.storage (500 Terabytes in total). The rest is a mix from a large research dataset in Life Sciences, Healthcare, Environment and Internet (see composition here and Messari report here).
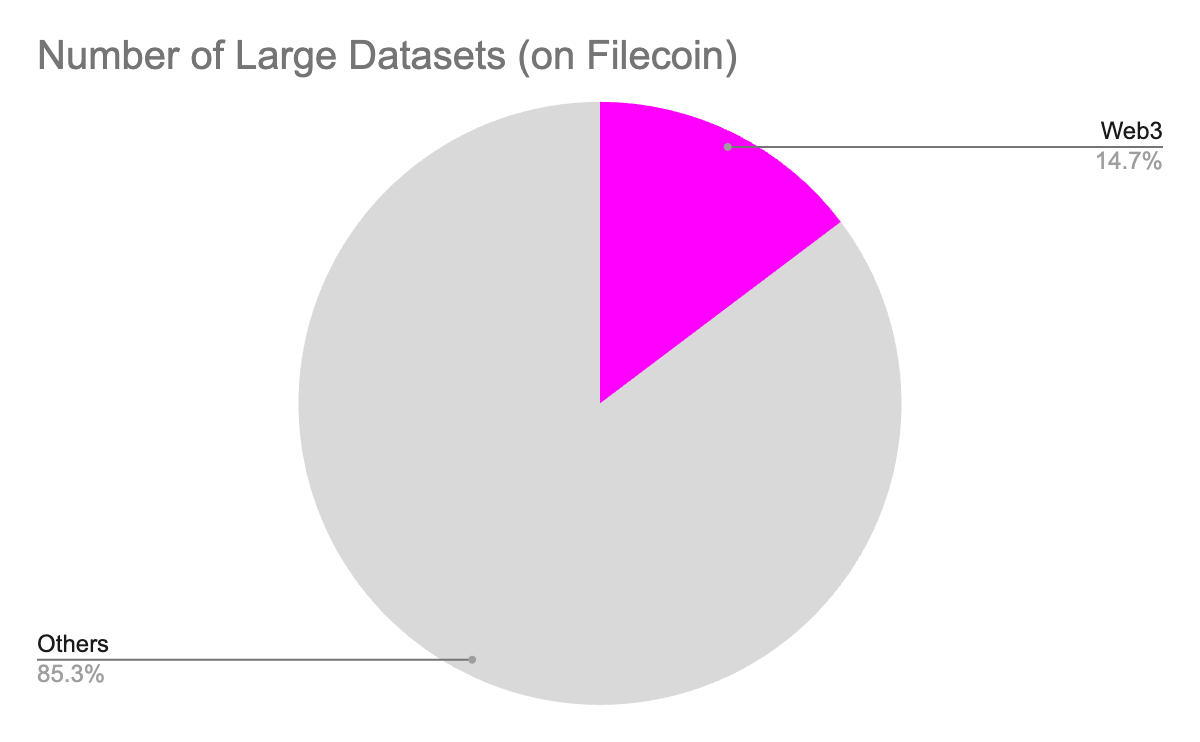
Proportion of Web3 / Crypto projects in Filecoin Plus program
Arweave, with an innovative fee structure (pay once for permanent storage), and better scaling mechanisms pioneered by the likes of Irys (previously Bundlr), has seen more adoption with “DApp” (decentralized applications) developers. In particular, it became the storage location for “on-chain media,” supporting developers building new consumer applications powered by Web3 ownership (login with your wallet, collecting posts, articles, podcasts, etc.). We estimate that 100 Tb (~65% of Arweave) is related to “Web3 Social”.
A great example of a decentralized social protocol that adopted the blockchain as an immutable database to guarantee “switching powers” to its users is Lens Protocol. Its team pushed the envelope of on-chain data scaling by building its own L3 on Araweave called Momoka.
Data from consumer crypto applications stored on Arweave
Multi-modality social datasets
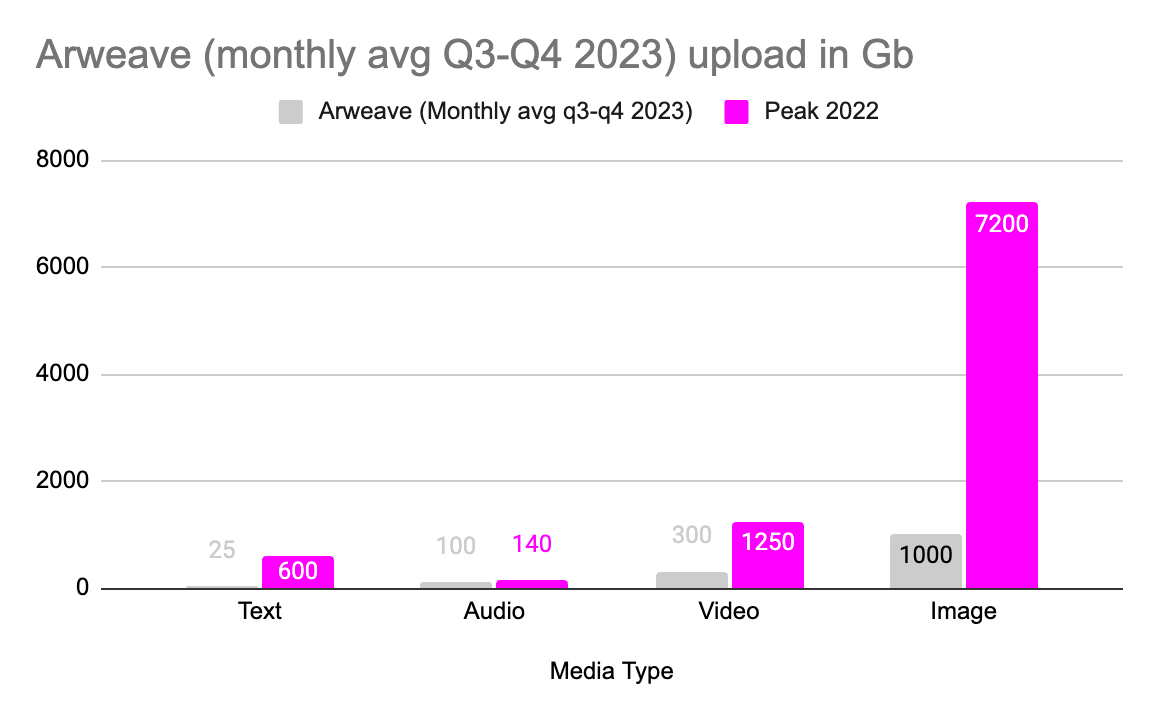
Monthly average data size uploads to Arweave by media modality
Over the last two years, we’ve seen the emergence of more and more applications leveraging “onchain history” that users constructed by collecting NFTs into their wallets. This is becoming a powerful trend for two reasons:
- The items that a crypto user can collect are no longer limited to basic profile NFTs (“PFPs”) but can now span any media type imaginable. An NFT nowadays can be a social media post on Lens, a podcast on Pods, a song on Sound, a video on Odysee, or a ticket to a real event like a POAP.
- This onchain history is also linked to other Web3 users, effectively creating large “social graphs” without silos. As more and more applications get built on top of crypto trails, either directly like on Lens (where a follow leaves a trace because it interacts with a smart contract) or Ethereum Follow Protocol or indirectly, like in the case of Warpcast (every user get a new wallet behind the scene).
This trend has been underpinning data growth on Arweave. At the peak of the cycle in 2022, 7.2 TB of NFTs, and 1.25 TB of video were uploaded per month.

It is worth noting that incentives exist for different actors to start bringing web2 data into these storage solutions for archiving purposes. We have already seen more than 1 TB of Web2 data from Wibo, Reddit, Twitter, Nostr, YouTube, and TikTok being uploaded to Arweave.
Data volumes picking up in 2024
Putting on the data science hat again and following the data, we can see an uptick in video uploads on Arweave this January (2024). With protocols like Lens opening up to any user, we expect social media posts to grow even more, with a focus on game and event streaming.
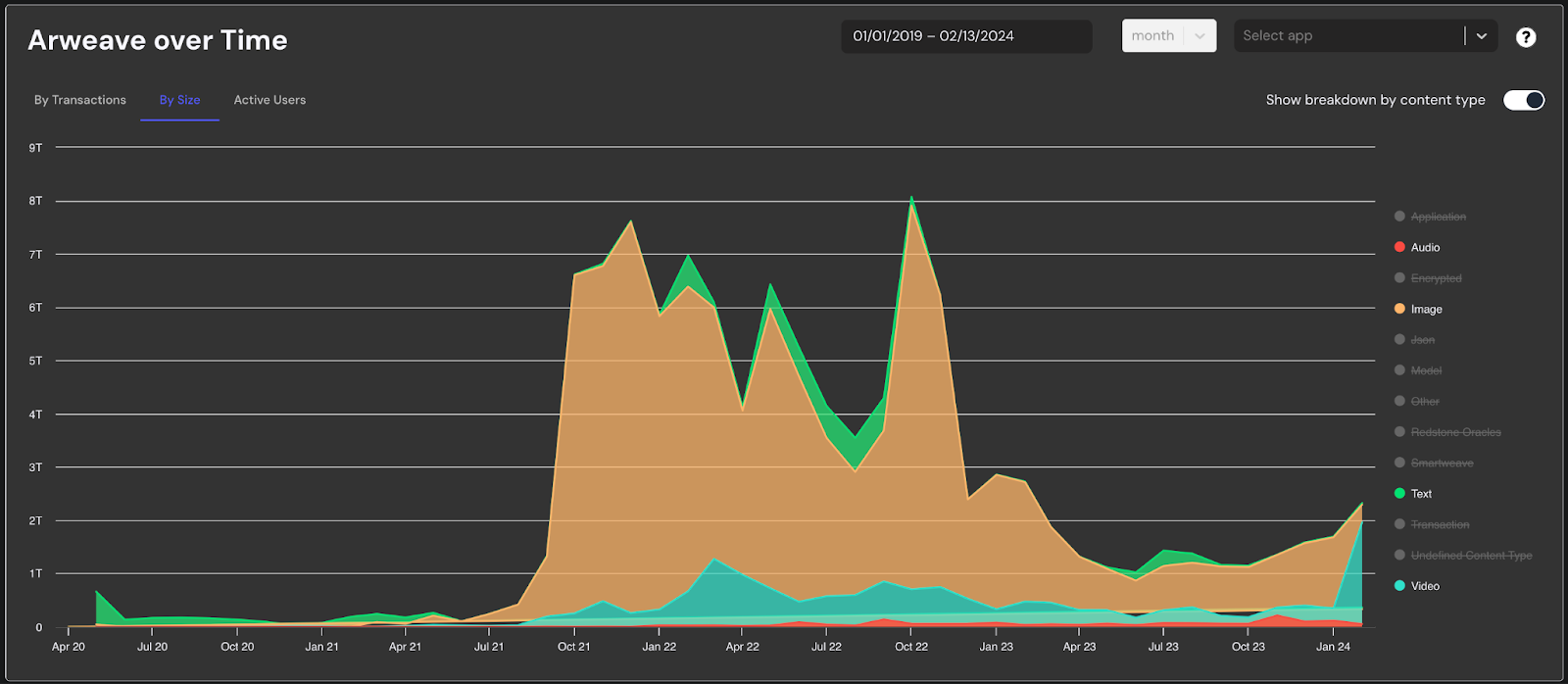
Historical monthly data size upload to Arweave by media modality, courtesy of DataOS team.
It is amazing that Filecoin and Arweave have amassed an open dataset the size of Wikipedia in only a few years, with strong guarantees around its preservation! Even with a conservative estimate of data 4X over the next 2 years, we should see a 500TB Web3 social dataset on Arweave specifically eclipsing Wikipedia by a margin. The data will be enough to train a model like ChatGPT on text alone (or 10X bigger if using all modalities; see how much data needed to train ChatGPT).
The future of Web3 social data
Long-form and short-term video formats
Zooming out, it seems we are at the early innings of a mega trend where
- Smart contract innovation drives data growth in ecosystems like Arweave, and
- NFTs have provided a way to tokenize media and has thereby driven the proliferation of new applications.
Following the steps of Web2, I believe the next wave will be driven by video-enabled apps (decentralized “YouTubes " and “TikTok”). Many category leaders have already emerged, like Odysee, which boasts some 5 million monthly active users despite all the headwinds the underlying blockchain LBRY supporting it had faced.
Actually, many famous YouTubers with millions of followers, foreseeing the censorship risks of closed-off platforms, have started actively building their audiences on Odysee as a hedge, in some cases already achieving 5 to 6-figure follower counts.

AI for Web3 data
As Web3 data size grows, some unique challenges and opportunities arise from a Data Scientist perspective.
Content moderation
The monetary aspects of crypto do attract bad actors, spammers, and low-quality users (“airdrop farmers”), all of whom can dilute the value of the data created. Fortunately, AI techniques are showing good results in filtering out bot-generated content, for example, using network and semantic analysis. A caveat to that is that you need a good enough ground truth dataset to be collected.
We have been running LLM-like models fine-tuned on 100m X/Twitter tweets at mbd to analyze the Farcaster ecosystem. We can say that Web2 AI models must be adapted to Web3 as cultural norms differ.
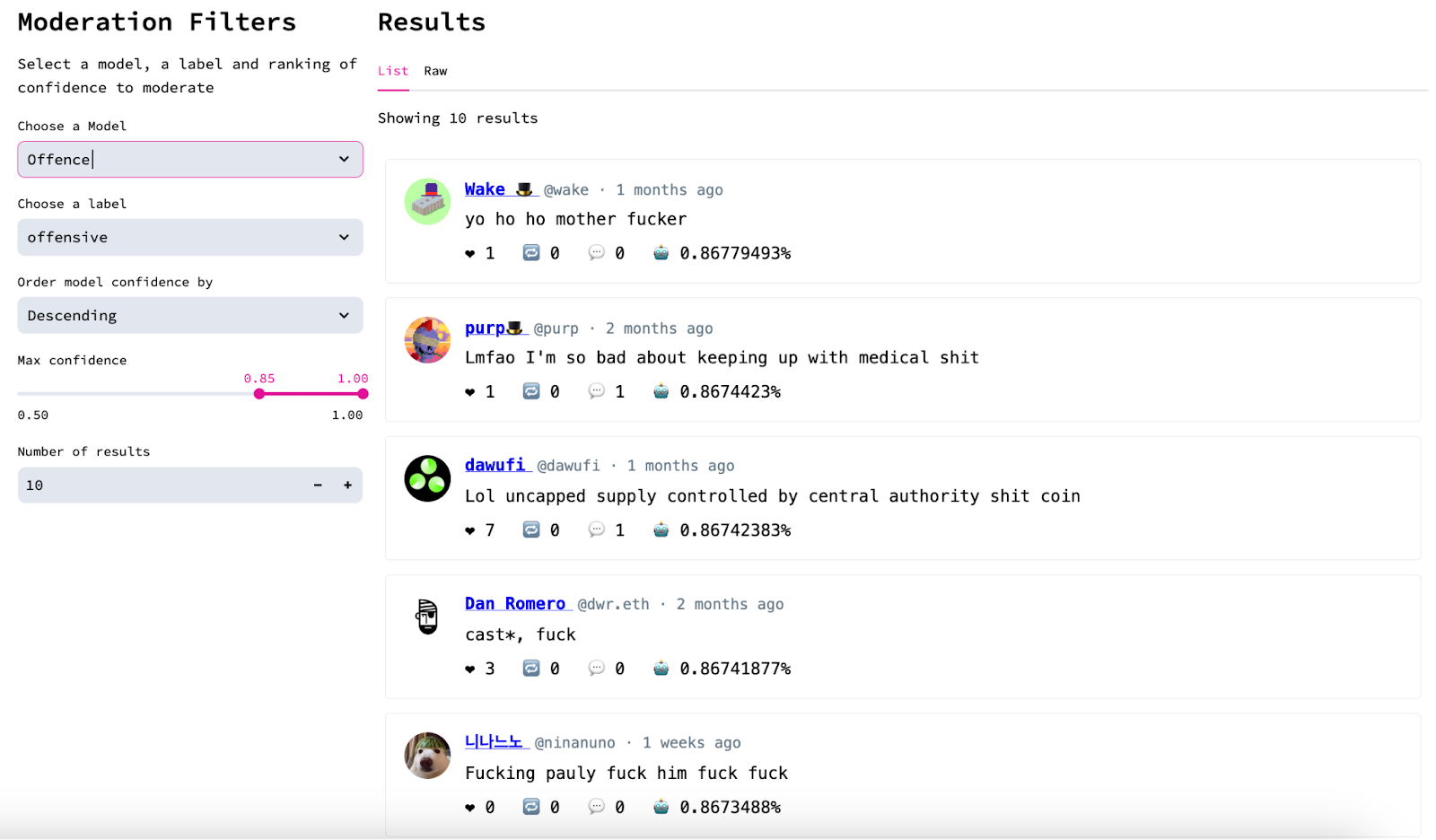
Example of TweetNLP model (academic model trained on 100M tweets) top results for the “offensive” label, largely detecting “shitposting” and misclassifying it (among other false positives)
Content personalization
As data size grows, discoverability becomes a problem, especially because decentralized storage solutions are hard to index and were not designed for “personalized read.” Luckily, again, many techniques related to recommendation systems have been pioneered by social media companies over the past 20 years that make mining this data efficient.
AI can be used to understand this vast data lake and assist in exploring it. This has the potential to surface many of the great conversations happening in Web3 now that most people are unaware of.
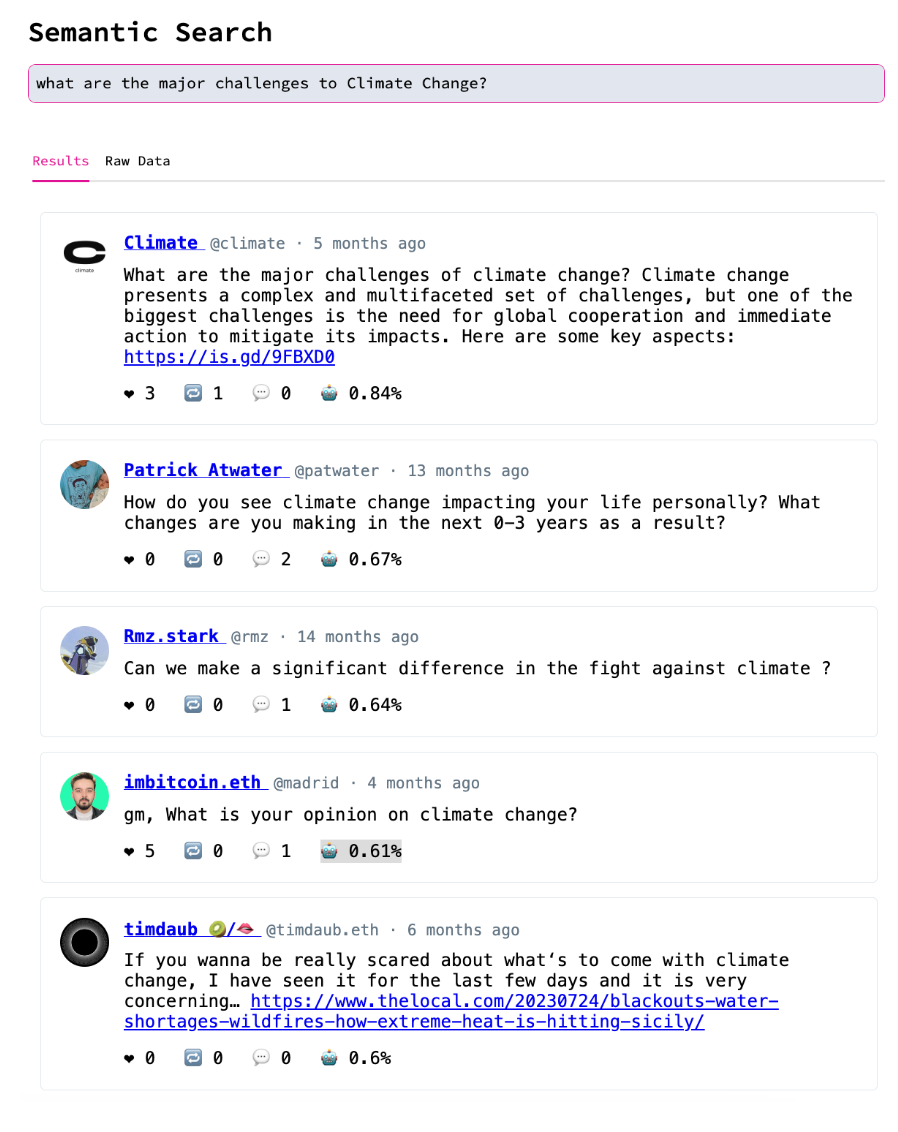
AI used to surface results based on a natural language query
Our early results, leveraging the wider crypto association between users as they collect NFTs, posts, and articles, are promising. Custom models fine-tuned on Farcaster data can predict what people will like, share, or reply to with high accuracy, making creating algorithmic feeds that can generate engagement a reality for Web3 developers for the first time.
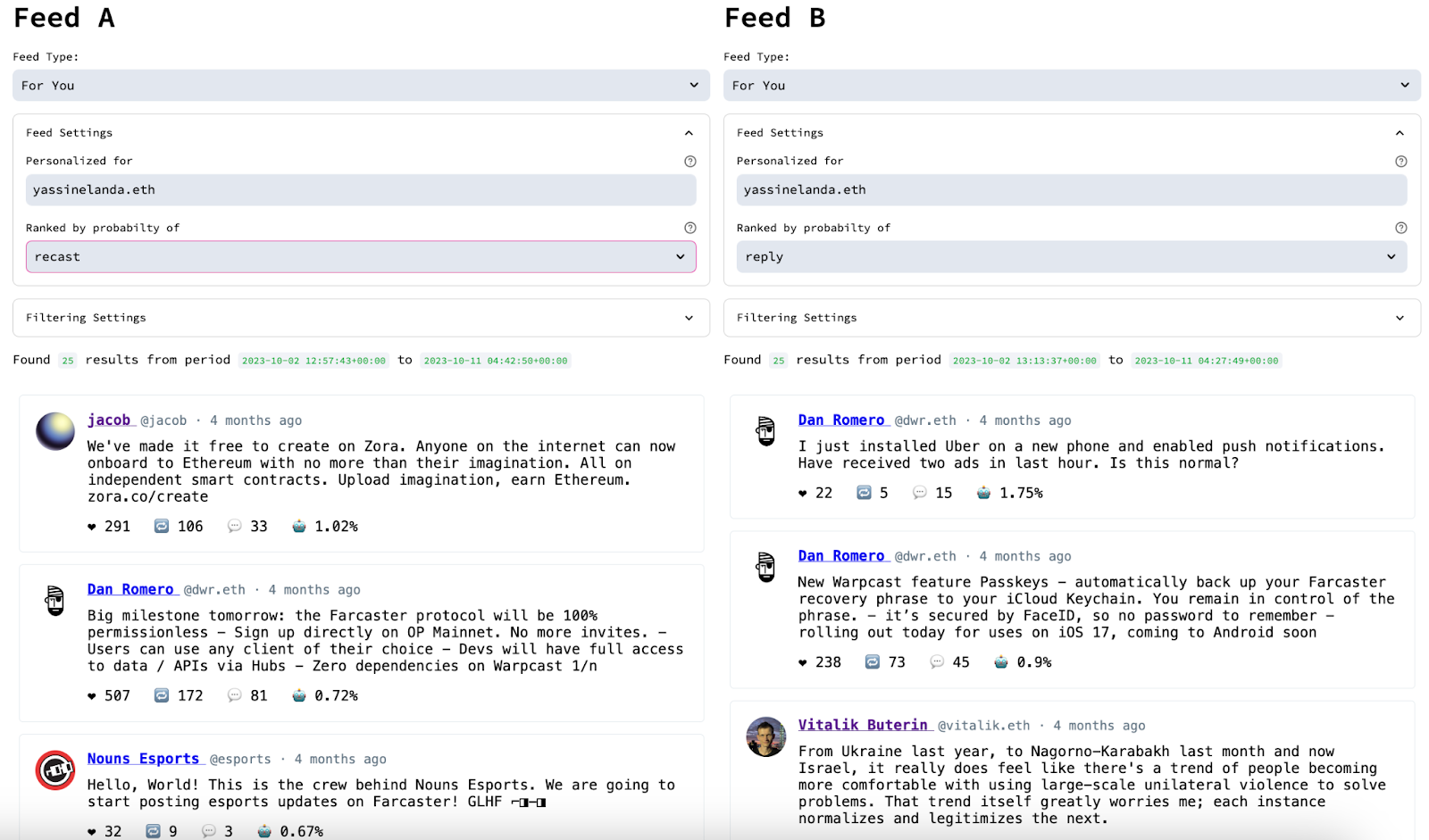
Example of AI feed builders of Web3 data. Feed comparator between two methods of ranking: “sharing” vs “replying” for the same user.
The challenge here, is to try and avoid the pitfalls of using machine learning blindly but to empower the developers and users to explore the “algorithmic feed design space” and offer different discovery mechanisms that align with their values or their community values.
Content Generation
Last, we live in a data-hungry world where the competitive advantage between AI models does not lie in their sizes or the amount of compute available to companies (after a certain hurdle is passed) but in the quality and uniqueness of the datasets trained on.
Building content generation models tailored to the Web3 audience and complementing more mainstream ones with this data helps brands appeal to a growing audience. It is an awesome opportunity (that I am excited to be working on!).. especially when you couple AI training with incentive mechanisms to keep solving the long-tail AI problem, concepts Web3 developers have pioneered and excelled at.