How AI Algorithms Work in Social Media


Ever wondered how data populates your social media feeds? Who decides what images, videos, and posts you see? It’s not random, but determined by an AI algorithm(or AI model) working in the background. The AI model analyzes all the content you engage with and what others similar to you engage with and then shows the content you are most likely to click on. It combines demographic factors like location, age, gender, and your profile preferences with your past behavior—like the video you watched till the end, the post you commented on and the ad you clicked. The AI model attempts to predict the next post you’ll pay attention to using all these different data points.
This article explores how AI works in social media. We also discuss challenges and how Web3 can help.
Summary of key concepts in Social Media AI algorithms
| Concept | Meaning |
| Session-based modeling | AI model predicts the best post you can watch when you are scrolling through your feed. |
| Uplift modeling | AI model predicts posts that address multiple specific objectives |
| Exploration vs. Exploitation | Exploration means you search and watch the content of your choosing. Exploitation is the paradigm where the AI model pushes certain content to you just because you engaged with similar content in the past. |
| Challenges | Lack of transparency and accountability. Social media generating negativity instead of positive social connections. |
| Solutions | Alternative models, Web 3 paradigm |
Session-based modeling
Big companies like Amazon, TikTok, and Netflix all have AI systems working on the principles of “session-based modeling.”
Here’s an example: Imagine you’re looking for a cool Punk NFT, and you click on a few of them. The AI model occasionally shows you something new to see if it grabs your attention. It shows you a doggy NFTs and you click on it.
But what happens next? If you return to the main screen or the system wants to send you a special message, should it show you more Punks? Or Doggies?
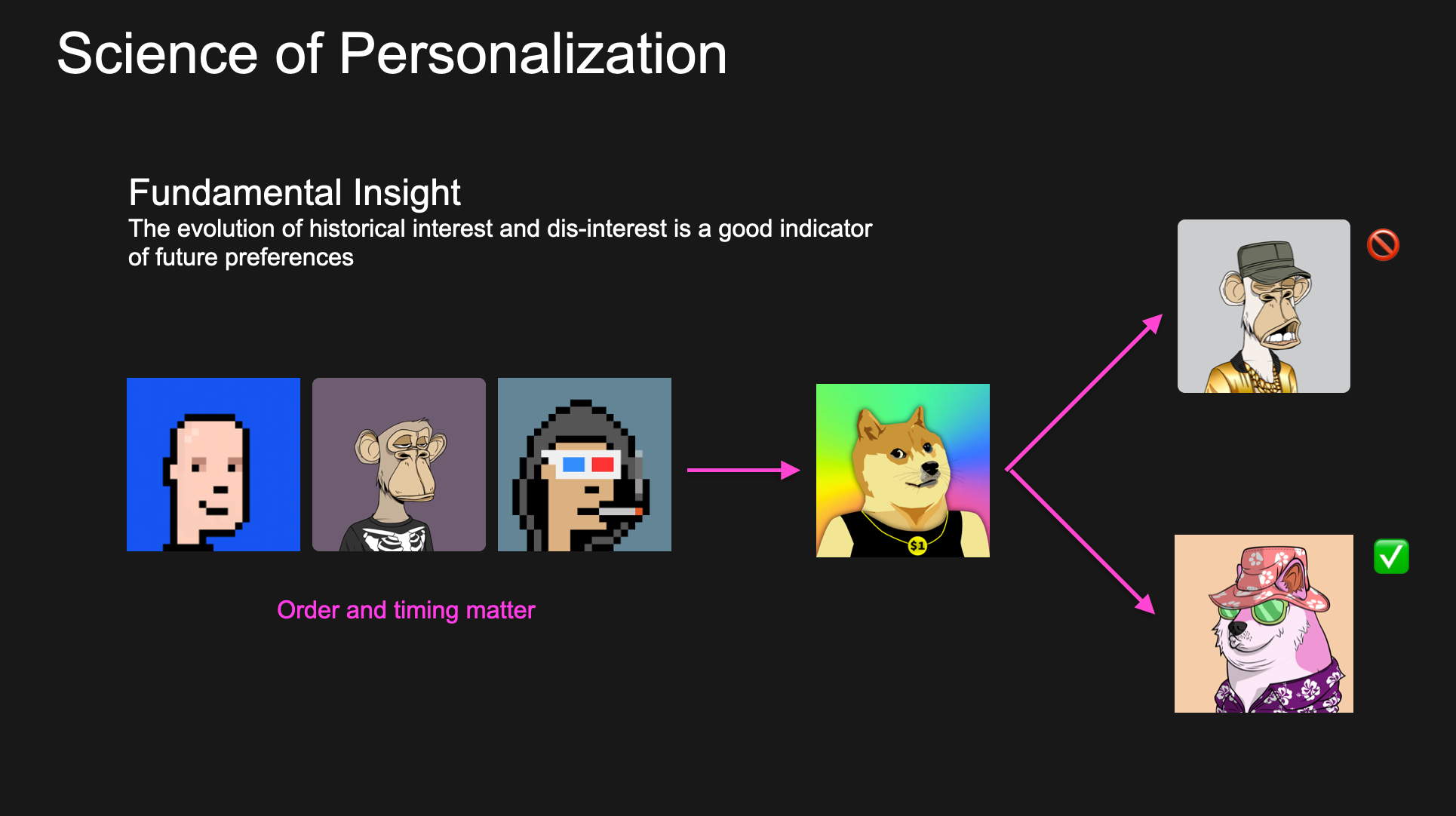
This is where the magic happens. The AI model must figure out what you’re more interested in as of right now. It learns what you like as you click around and try to guess what you want to see next. And the more you interact with content, the smarter it gets!
In the best systems, the learning happens in real time. If you suddenly change your mind and return to looking at Punk NFTs, the system will update quickly and show you more Punks again.
The people who build these AI models test them out constantly. For example, they might hide a week’s worth of your clicks and see if the system can still guess what you want based on what you did before. And guess what? With just 5 to 10 clicks, the model figures out what you want to see about 90% of the time! As a user, if you disappear from the network for some time, the recommendations may not be well suited to your current interests when you returned. That’s why social media creators have to post frequently so their content gets a chance to be “trialled” out on maximum number of social users.
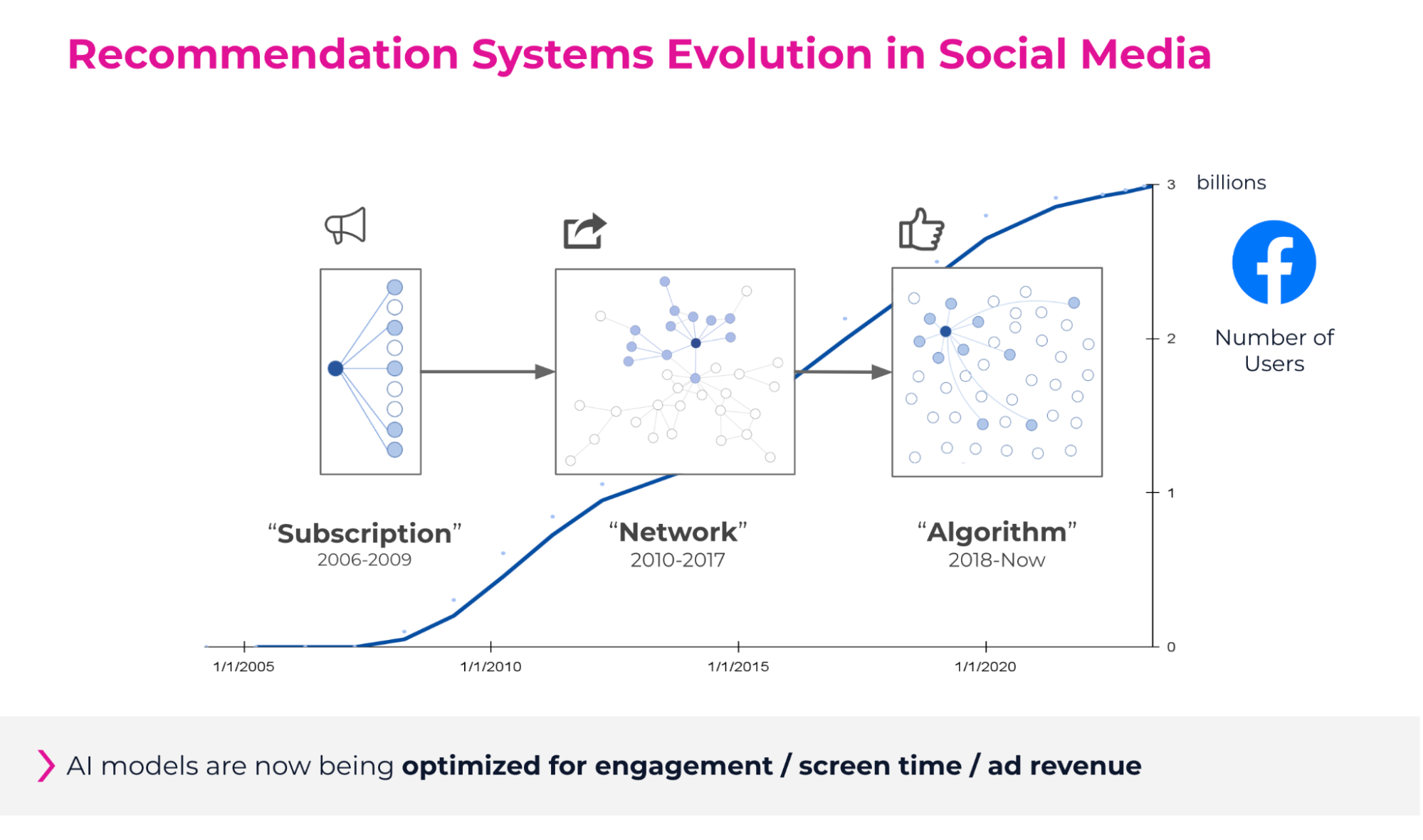
Evolution of Social Media Algorithms: The Facebook & X/Twitter Example
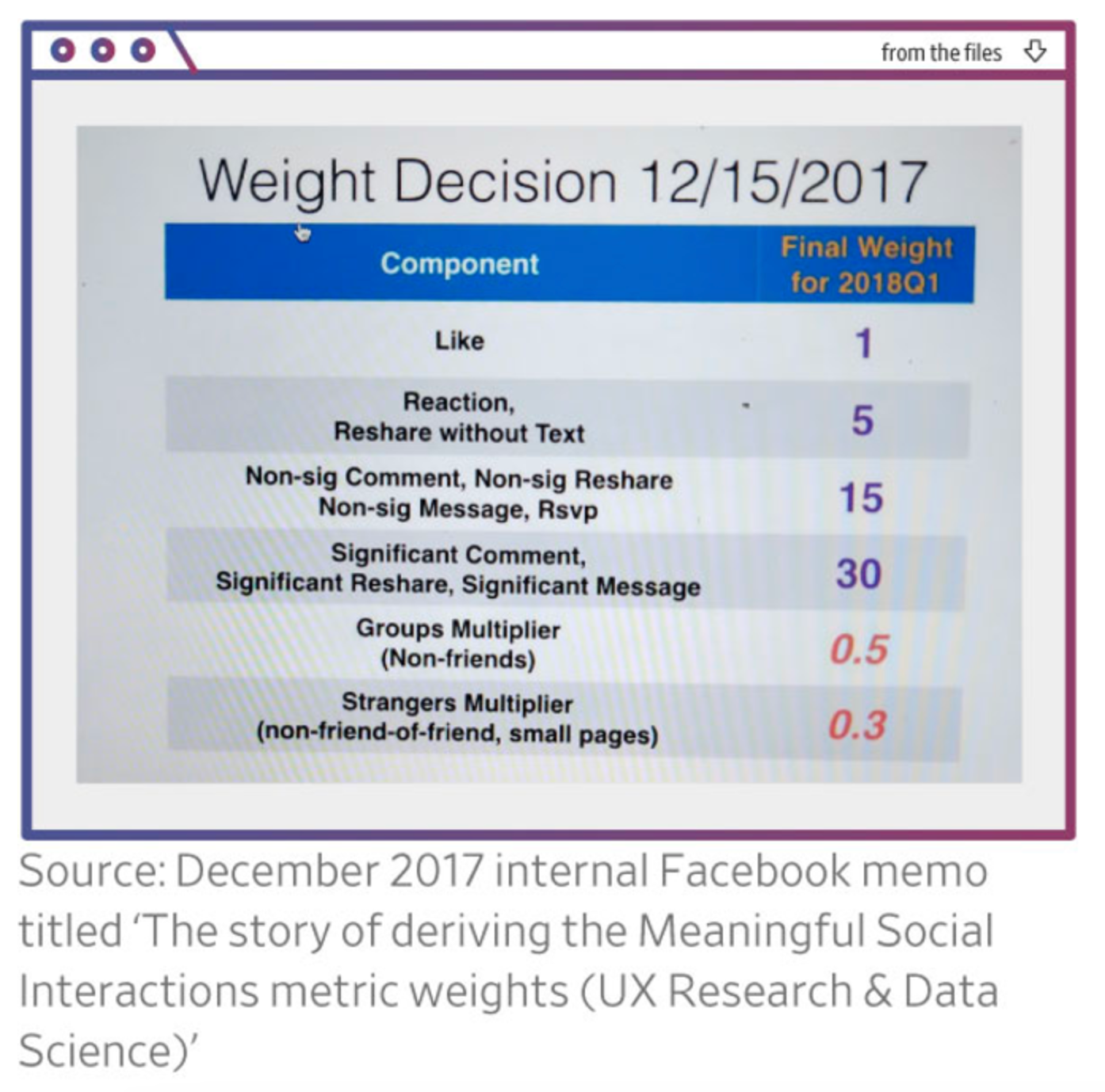
Social media companies have been using AI models for a long time and use even more complex strategies to figure out what’s most important to show you. For example, in 2018, Facebook made a big change to its algorithm by introducing “meaningful social interactions” (MSIs). The idea was to show users more posts from friends and family instead of businesses or media. The algorithm gave each possible post a score based on how likely the user will like, comment, or interact with it. Today, more models are involved—each trained on one specific interaction (likes vs. comments) & combined using human judgment.
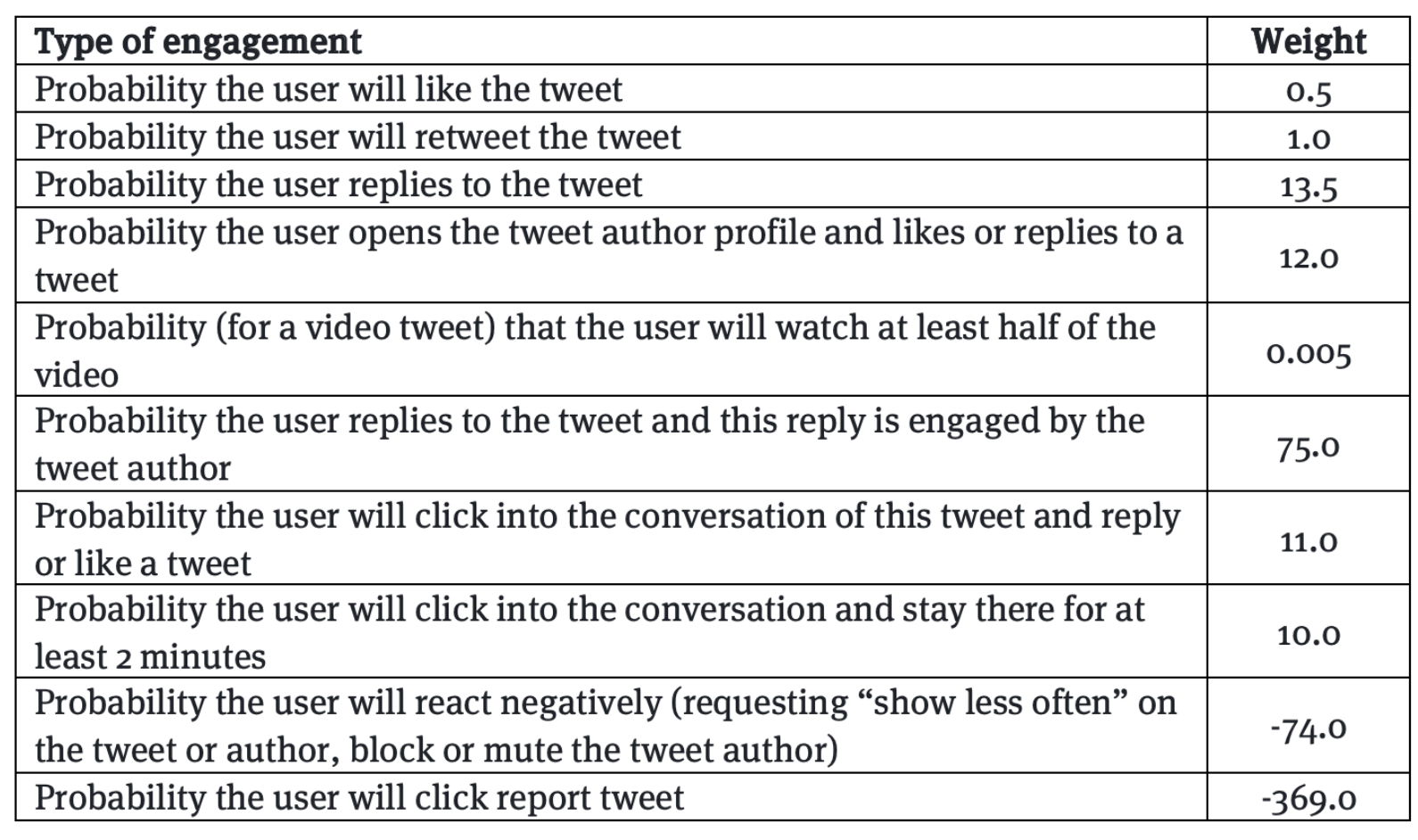
Of course, big companies do not publish the secret workings of their AI models. Publicly available information is derived from Facebook’s secrets leaked in 2017. We could also derive weights from X (formally Twitter) based on their open-source code.
Uplift modeling
Musk twitter post
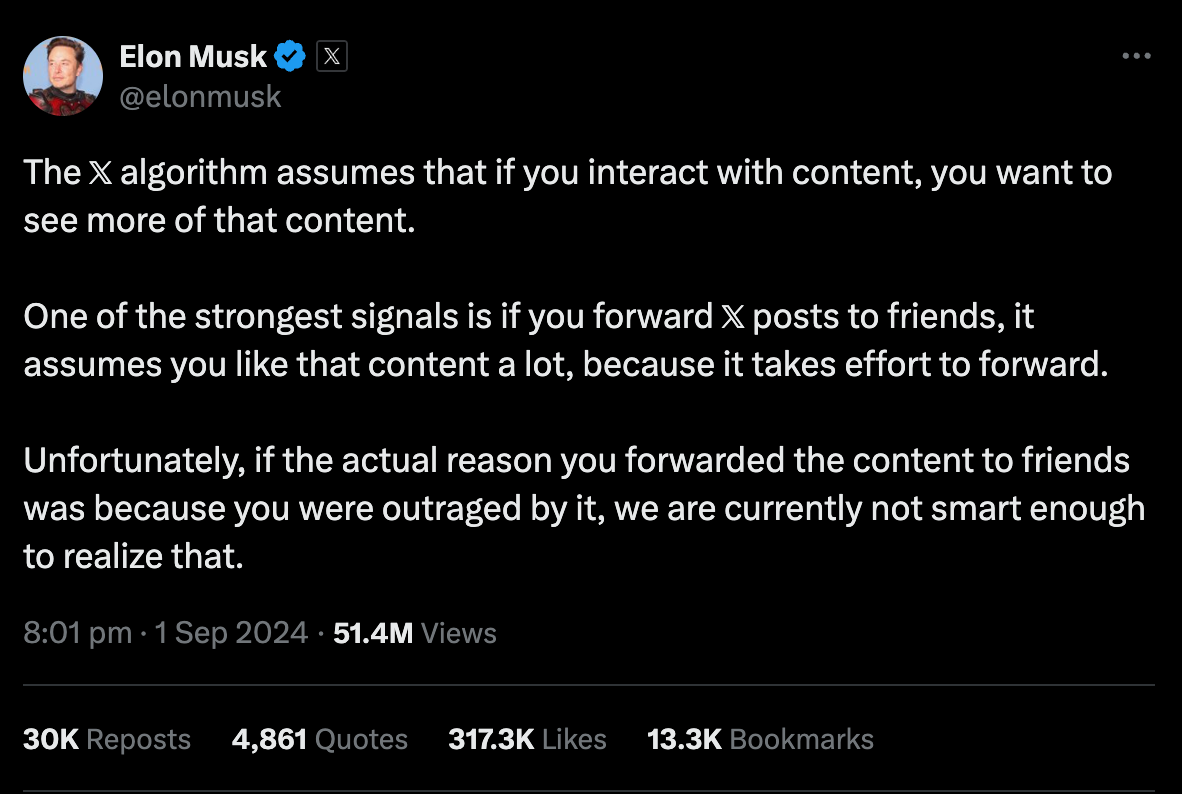
Even though platforms wanted to create more positive interactions, their models also ended up pushing viral content that made people angry or upset, because those post types also tend to get a lot of comments and shares. It felt like the model explicitly targeted what made people “tick.”
As competition increased, social media companies became more aggressive in their attempts to capture user attention and convert to sales. They began adding more layers of optimization to extract value on top of engagement predictions. Social media AI models were given more “objective functions.” For example, the AI should recommend posts so that the user
- Spends more time on the screen
- Buys more at each session
- Responds yes to a brand awareness survey after seeing an ad
This is called uplift modeling and was a big part of what I built early in my career.
To understand uplift modeling better, let’s get back to our NFT recommendation example and now assume that the platform has injected another objective function into the AI to increase the transaction size per user (they make fees on it!).
The system picked up your new interest in Doggy NFTs. Based on its calculations, it understood you really like the berry hat this Doge has (or another rarity trait in web3 talk). However, it knows another Doggy NFT, which is a bit lower quality but sells for a higher price and shows you that instead! This explains why so many of us buy things we don’t necessarily like or find it hard sometimes to find budget items online!

Custom optimization functions introduce at least three main negative dynamics:
- Randomized content discovery: Platforms started seeking content from everyone to expand the chances of showing you something that will keep you glued. Forget your friends and people you follow; your feed is populated by random people going viral.
- Emotional and polarizing content: Optimizing for something else that is not strictly what users click on seems to have the negative effect of pushing more emotional, polarizing, and fear-spreading content. Users don't understand that these algorithms are simply pushing content to get a reaction out of them.
- System complexity and opacity: The system is complex, opaque, and hard to understand. Even in cases where the core code is open source, like with X, the AI model code (like the ads optimization engine) is not shared publicly.
These trends have been exacerbated since the emergence of TikTok (short videos on auto-play from all creators!) Stagnating platforms like Facebook have to respond in kind: moving from your friends' walls to short videos from all across the globe to keep you engaged.
Accountability and transparency in algorithm design
This also raises the question of who should be making these decisions. How do we make these algorithms more transparent? And more importantly, who gets the blame if something harmful happens? Legal scholars, investors, governments, and companies are battling this in courts now. The gist of the debate is whether we hold platforms accountable when something unfortunate happens - like a kid dying because they watched a TikTok video - a true story currently in court). Unfortunately, as of now, a platform featuring user-generated content is under “section 230”. They are granted immunity from being sued over content published by those users.

On this question, there are a few different viewpoints and solutions proposed:
- Those who see platforms as responsible—not only for distributing but also for making editorial decisions—want to see them regulated or at least open source their algorithms or make them accessible to academia for scrutiny.
Some advocate for creating an “Algorithms Store” similar to an app store to empower users to choose what they want. The main argument is that users don’t want to do it and would rather stay passive and consume content.
The Promise of Web3 Social Platforms
Unfortunately, I have little faith in government regulation or in the capacity of centralized platforms to self-regulate. Instead, I believe in a third way: incentivized regulation. It starts by acknowledging that algorithms are just powerful tools that hyper-personalize distribution. However, like any technology, they are not neutral. The algorithm designers have the responsibility to make them explainable, transparent, decentralized, and verifiable.
Customers are smarter than we think, and should be allowed to control their feeds. Imagine if social media apps let you “really” choose your algorithms, and you decide to hide all the interesting content, there is a realistic situation, especially on small networks like Farcaster, where there would be nothing for you to see today and you are better off closing the app and going for a walk or reading a book. Would the current platforms ever let you do that?
Ranking systems should also be more tightly integrated with content moderation systems. These two for now live in different teams (one under the money-making branch of the organization, and the other is usually an after thought).
This is why Web3 social is so important.
For example, on Farcaster, the distribution of user engagement (like, reply, share, post) since June is as follows:
- Users with less than 2 interactions: 30996
- Users with 2 to 15 interactions: 107784
- Users with 16 to 31 interactions: 25528
- Users with more than 31 interactions: 49937
AI algorithms can already predict what you would do with very high accuracy for majority of the network. The more users interact with content, the better the models get.
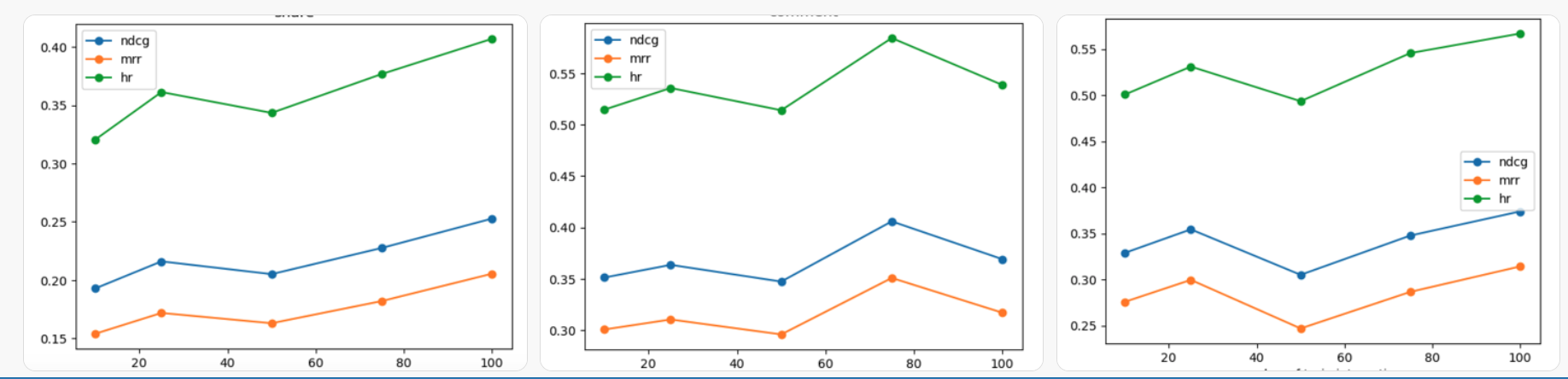
@mbd results showing relevancy metrics (rank of posts people click on) for different buckets of users & interactions on Farcaster
We have all the basics in place to run some serious experiments. Because the social graph is open, more ideas like “bridging algorithms” that build mutual understanding and trust across differing perspectives can be implemented and tried.
@mbd, we’re building the tools to keep social media AI algorithms open for participation!
Additional Resources
If you are interested in this topic, there are some great resources that I am linking here:
- https://knightcolumbia.org/content/understanding-social-media-recommendation-algorithms
- https://knightcolumbia.org/blog/twitter-showed-us-its-algorithm-what-does-it-tell-us
- https://partnershiponai.org/beyond-engagement-aligning-algorithmic-recommendations-with-prosocial-goals/
- AI models Harari Podcast
- Podcast on Tiktok accountability by ex Facebook employee